Este documento recopila las lecciones aprendidas durante el desarrollo del proyecto Melody, derivadas de la experiencia práctica, decisiones arquitectónicas tomadas y desafíos enfrentados. Estas lecciones proporcionan insights valiosos para futuros desarrollos y mejoras del sistema.
Gestión y Organización
Las lecciones más importantes del proyecto están relacionadas con la organización del equipo y la gestión del trabajo. La experiencia demostró que una buena organización puede ser más determinante para el éxito del proyecto que las decisiones técnicas individuales.
Para más detalles sobre cómo se organizó el equipo y los checkpoints del proyecto, ver Organización y Distribución del Equipo y Sprints y Checkpoints.
Comunicación y Coordinación
Al inicio del proyecto, la falta de comunicación clara entre los miembros del equipo generó un desbalance significativo: 4 desarrolladores trabajando principalmente en backend mientras solo 1 desarrolladora trabajaba en frontend. Esto se debió tanto a la necesidad de establecer la infraestructura inicial como a una mala organización y comunicación entre los miembros del equipo. Para más detalles sobre la evolución de la organización del equipo, ver Organización y Distribución - Evolución de la Organización.
Lección: La comunicación clara y constante es esencial desde el inicio del proyecto. La falta de comunicación puede generar desbalances en la distribución del trabajo que son difíciles de corregir después y afectan significativamente el progreso del proyecto.
Dailies Asíncronas
A partir del checkpoint 3, se establecieron dailies asíncronas en Discord siguiendo un formato estructurado (Ayer, Hoy, Norte, Bloqueo). Esta práctica transformó la dinámica del equipo, permitiendo estimar y cerrar historias mucho más rápido y eficientemente. Cada miembro comenzó a realizar sus tareas sin trabas y con feedback constante del resto del equipo. Para más detalles sobre el formato y los resultados, ver Organización y Distribución - Dailies Asíncronas.
Lección: Las dailies asíncronas pueden ser extremadamente efectivas, especialmente en equipos distribuidos o con horarios flexibles. No solo mejoran la comunicación, sino que también ayudan a definir mejor el scope de los sprints y permiten identificar bloqueos tempranamente. El formato estructurado es clave para su efectividad.
Distribución de Responsabilidades
La reorganización del equipo en el checkpoint 3, donde se definieron claramente las responsabilidades de cada miembro (backend exclusivo, frontend exclusivo, full stack), mejoró significativamente la eficiencia. Esto permitió reducir el atraso del frontend considerablemente y mejorar el progreso general del proyecto.
Lección: Definir claramente quién hace qué desde el inicio, o al menos tan pronto como sea posible, mejora significativamente la eficiencia del equipo. Es mejor tener roles bien definidos que intentar que todos hagan todo, especialmente cuando hay desbalances en la carga de trabajo.
Equilibrio Backend/Frontend
El desbalance inicial entre backend y frontend (4 desarrolladores vs 1) generó problemas significativos. Aunque se necesitaba establecer la infraestructura inicial, el exceso de trabajo en backend mientras el frontend se atrasaba creó una deuda que fue difícil de recuperar.
Lección: Es crucial mantener un equilibrio razonable entre backend y frontend desde el inicio, o al menos planificar cómo se va a manejar el desbalance temporal. Priorizar demasiado una parte del stack puede crear problemas que son difíciles de resolver después.
Gestión de Historias de Usuario
Fue muy difícil cerrar las historias de usuario debido a las muchas dependencias entre ellas. Algunas historias tardaron dos checkpoints enteros hasta tener funcionalidades completas. El equipo intentó usar Linear para gestionar las historias más importantes, pero resultó más útil utilizar un Excel compartido con los profesores. Para más detalles sobre la gestión de historias y los checkpoints, ver Sprints y Checkpoints.
Lección: Las herramientas simples pueden ser más efectivas que las sofisticadas. Un Excel compartido puede ser más práctico que herramientas más complejas como Linear cuando se necesita colaboración directa y seguimiento simple. Es importante identificar y gestionar las dependencias entre historias desde el inicio para evitar que se acumulen.
Desarrollo Iterativo y Reorganización
El proyecto siguió un enfoque iterativo con 4 checkpoints, permitiendo ajustes y mejoras continuas. La reorganización del equipo en el checkpoint 3 fue un punto de inflexión que demostró la importancia de estar dispuesto a cambiar la organización cuando algo no funciona. Para más detalles sobre los checkpoints y la reorganización, ver Sprints y Checkpoints - Checkpoint 3 y Organización y Distribución - Reorganización.
Lección: Un enfoque iterativo permite aprender y ajustar durante el desarrollo, pero es crucial estar dispuesto a reorganizar el equipo y cambiar estrategias cuando algo no está funcionando. Esperar demasiado tiempo para hacer cambios organizacionales puede resultar en problemas difíciles de resolver.
Arquitectura y Diseño
Separación de Responsabilidades
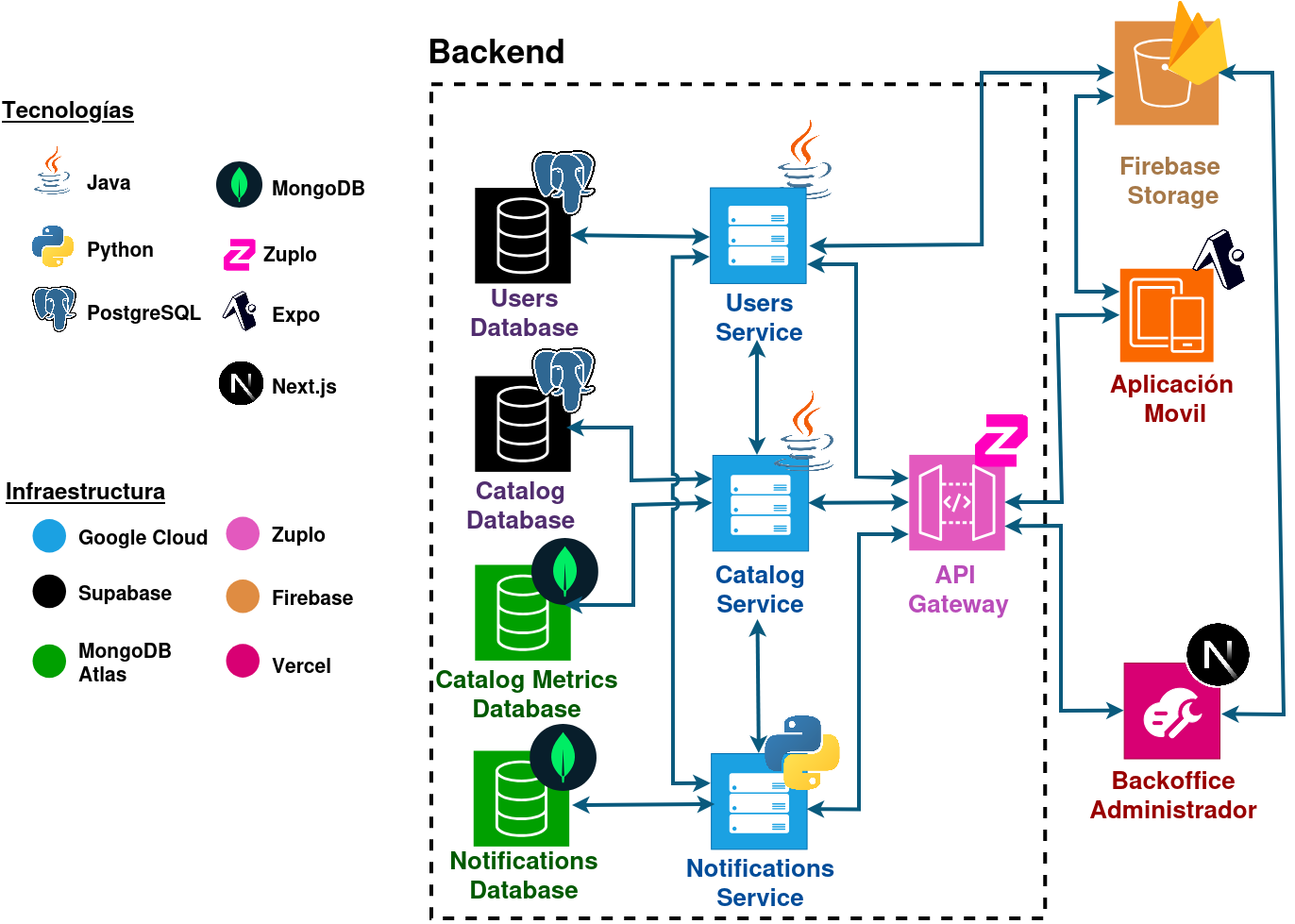
Una de las lecciones más importantes aprendidas es la importancia de mantener una separación clara de responsabilidades entre servicios. El servicio de métricas actualmente está integrado dentro del servicio de catálogo, lo cual funcionó para el desarrollo inicial, pero ha demostrado que una separación más temprana habría facilitado el mantenimiento y la escalabilidad independiente.
Lección: Aunque es tentador integrar funcionalidades relacionadas en un mismo servicio para simplificar el desarrollo inicial, es importante evaluar si las responsabilidades son lo suficientemente distintas como para justificar servicios separados. Esto es especialmente relevante cuando diferentes componentes tienen diferentes patrones de escalabilidad o requisitos de rendimiento.
Arquitectura en Capas
La implementación de una arquitectura basada en capas (Controller-Service-Repository) en cada servicio, como se describe en la vista general de servicios, ha demostrado ser una decisión acertada. Esta separación ha facilitado el mantenimiento, las pruebas y la evolución del código.
Lección: Una arquitectura bien definida desde el inicio, aunque requiera más planificación inicial, paga dividendos significativos en términos de mantenibilidad y capacidad de evolución del sistema.
Comunicación entre Servicios
La elección de usar APIs REST síncronas para la mayoría de las comunicaciones y webhooks asíncronos para eventos, como se implementa en el Servicio de notificaciones, ha demostrado ser un buen balance entre simplicidad y funcionalidad.
Lección: No siempre es necesario implementar sistemas de mensajería complejos desde el inicio. Los webhooks HTTP pueden ser suficientes para muchos casos de uso y son más simples de implementar y debuggear, especialmente en contextos donde el volumen de eventos es manejable. Esta misma filosofía de simplicidad pudo haberse aplicado desde el principio también para el manejo de métricas, comenzando con una solución más simple y escalando la complejidad solo cuando fuera necesario.
Gestión de Datos
Database per Service
La decisión de implementar “Database per Service”, donde cada servicio gestiona su propia base de datos (como se detalla en la Arquitectura) ha demostrado ser fundamental para la independencia y escalabilidad de los servicios.
{kind=link}
Lección: Aunque esta arquitectura introduce complejidad en términos de consistencia de datos y comunicación entre servicios, los beneficios en términos de independencia, escalabilidad y flexibilidad tecnológica justifican esta complejidad.
Elección de Tecnologías de Base de Datos
El uso de diferentes bases de datos según el caso de uso (PostgreSQL para datos relacionales, MongoDB para métricas y notificaciones) ha demostrado ser efectivo. Cada base de datos se utiliza donde sus fortalezas son más relevantes.
Lección: No hay una solución única para todos los casos de uso. Elegir la tecnología de base de datos adecuada para cada servicio basándose en sus requisitos específicos puede resultar en mejor rendimiento y simplicidad de implementación.
Agregaciones y Optimización
La implementación de una arquitectura de dos niveles en el servicio de métricas (eventos individuales y agregaciones diarias) ha demostrado ser efectiva para balancear la necesidad de datos detallados con el rendimiento de consultas. Sin embargo, se perdió mucho tiempo de desarrollo al implementar esta arquitectura compleja desde el inicio, cuando se podría haber comenzado con una solución más simple y optimizar después, ya que el volumen de datos que se llegó a manejar no justificaba esta complejidad inicial.
Lección: Es importante priorizar funcionalidad y tiempo de desarrollo antes de optimizar. Si no se llega a necesitar un volumen de datos muy grande, no vale la pena optimizar para eso. Es mejor tener una funcionalidad que funcione bien y luego optimizar si es necesario.
Desarrollo y Mantenibilidad
Uso de Inteligencia Artificial
Para llevar adelante el proyecto se utilizó bastante IA para generar código, documentación, etc. Esto fue muy útil para agilizar el desarrollo y reducir el tiempo de desarrollo. Sin embargo, se perdió mucho tiempo en corregir errores de IA y en entender el código generado en algunos casos puntuales. Por ejemplo, en el frontend se utilizó mucho IA para generar componentes lo que se desencadeno en problemas de performance. Por otro lado en el backend en catalogo se utilizó IA para generar entidades y repositorios lo que genero confusión en el modelado en algunos casos puntuales.
Leccion: Importante saber en que areas destaca la IA como tests unitarios, simples queries, parseos, validaciones y no tanto como modelado o diseño, cosas que reiquieren mas contexto y conocimiento.
Velocidad vs. Calidad
Durante el desarrollo rápido del proyecto, se crearon muchos componentes con funcionalidad similar en el frontend. Aunque se intentó minimizar esta duplicación, aún persisten componentes repetidos. Esto hizo que al final del proyecto se perdiese bastante tiempo en refactorizar y eliminar inconsistencias entre componentes.
Lección: Es importante balancear la velocidad de desarrollo con la calidad del código. Aunque es aceptable tener cierta deuda técnica durante el desarrollo inicial, es crucial planificar tiempo para refactorización y consolidación de componentes para evitar que la deuda técnica crezca descontroladamente.
Validaciones y Manejo de Errores
La falta de validaciones adecuadas en ciertos puntos del sistema (como la validación de tamaño de archivos) ha demostrado la importancia de implementar validaciones robustas desde el inicio.
Lección: Las validaciones y el manejo de errores deben ser considerados desde el diseño inicial, no como una adición posterior. Esto previene problemas de experiencia de usuario y reduce la necesidad de correcciones reactivas.
Procesamiento Asíncrono
La implementación de procesamiento asíncrono en el Servicio de notificaciones ha demostrado ser efectiva para operaciones que no requieren respuesta inmediata. Sin embargo, el procesamiento de métricas aún se realiza de forma síncrona en algunos casos.
Lección: Identificar operaciones que pueden realizarse de forma asíncrona desde el inicio puede mejorar significativamente el rendimiento y la experiencia del usuario. No todas las operaciones requieren una respuesta inmediata.
Seguridad
Algunas decisiones de seguridad fueron simplificadas durante el desarrollo inicial (como la falta de autenticación entre servicios en webhooks internos). Aunque esto fue aceptable para el contexto del proyecto, esta experiencia ha identificado áreas de mejora para entornos de producción.
Lección: Es importante documentar las limitaciones de seguridad conocidas y planificar mejoras de seguridad como parte de la hoja de ruta del proyecto, especialmente cuando se simplifican aspectos de seguridad para acelerar el desarrollo inicial.
Consideraciones para el Futuro
Basándose en estas lecciones aprendidas, se han identificado varias áreas de mejora que se documentan en los puntos de mejora. Estas mejoras representan oportunidades de optimización basadas en la experiencia práctica del desarrollo y operación del sistema.
La experiencia del proyecto ha demostrado que, aunque las decisiones iniciales fueron apropiadas para el contexto y alcance del proyecto, hay oportunidades significativas de mejora en términos de separación de servicios, optimización de rendimiento, y robustez del sistema que deberían considerarse para futuras iteraciones.